Notre sélection de données ouvertes utiles dans un Plan Alimentaire Territorial
Archive d’étiquettes pour : open data
Illustrer la donnée géographique, c’est tout un art…
Sommaire de l’article
Vous souhaitez démocratiser l’usage des données dans votre organisation à travers un portail open data mais vous ne savez pas quelles fonctionnalités prioriser ?
L’équipe Smart/Origin est là pour vous exposer les éléments indispensables d’un portail qui le rendront accessible et utilisable par tous les citoyens. Le contenu de cet article vous permettra également de dégager des premiers axes de rédaction des spécificités techniques du portail open data de votre organisation.
Il est indispensable de savoir sur quelles fonctionnalités investir afin de donner entière satisfaction aux utilisateurs.
Le premier point à investiguer avant de penser aux spécificités techniques du portail est le profil des utilisateurs qui viendront sur le portail et quelles seront leurs attentes et leurs usages de ce dernier.
Un portail open data pour les experts et les néophytes
Qui seront les utilisateurs du portail open data de votre organisation ? Vous serez les plus à même de les caractériser néanmoins nous pouvons vous donner deux pistes simples pour commencer : les utilisateurs experts de la donnée et les néophytes.
Les experts de la donnée
Les utilisateurs experts de la donnée savent utiliser et créer de la valeur à partir de jeux de données. Ces usagers sont des professionnels de la data : data scientists, chercheurs, géomaticiens…
Les experts de la donnée ont besoin d’accéder avec facilité à des datasets pertinents, standardisés et régulièrement mis à jour : ils conçoivent le portail open data comme une plateforme permettant d’exporter les données.
Les néophytes de la donnée
Un utilisateur néophyte conçoit le portail open data comme une source d’information sur les compétences d’une organisation. C’est un citoyen qui souhaite en apprendre plus sur une collectivité à travers les données qu’elle propose publiquement.
Il a besoin d’être projeté au cœur de la donnée pour en saisir les tenants et les aboutissants : il s’agit donc de remettre au centre du portail la visualisation des données et de proposer une forte éditorialisation afin de recontextualiser cette dernière.
Celle-ci doit donc être présentée à l’aide de datavisualisations qui rendent les informations principales claires et facilement compréhensibles. Les données présentées, comme pour les experts, doivent être pertinentes et utiles.

Au contact des territoires, nous avons pu constater une volonté forte des collectivités d’étendre les usages de leurs portails open data pour impliquer davantage les profils non experts de la donnée : citoyens, élus, décideurs, organisations…
Ces profils « grand public » ont des attentes très différentes ; ils attendent d’un portail une véritable expérience d’information, allant au-delà du simple catalogue de données brutes. Ils souhaitent notamment pouvoir accéder à des produits d’informations – réutilisations, data-visualisations, cartographies – leur permettant d’enrichir leurs connaissances et de s’approprier les données ouvertes par la collectivité.
La page d’accueil, une expérience commune pour tous les utilisateurs de votre portail
La page d’accueil est l’entrée du portail open data. Elle doit, en 3 secondes environ, donner envie au visiteur d’explorer l’offre thématique de jeux de données mise à sa disposition. C’est également sur la page d’accueil que vous pourrez mettre en valeur votre organisation et ses caractéristiques. La page d’accueil peut comporter plusieurs widgets permettant des usages variés et adaptés aux différents niveaux d’expertise des visiteurs. À vous de choisir ceux qui vous semblent les plus judicieux ! En voici quelques exemples :
Une mise en avant thématique
Inviter les visiteurs de votre portail open data à venir explorer les univers thématiques des compétences et données publiées par votre collectivité. Les thématiques couvertes par votre organisation peuvent pour ce faire être mise en avant via un menu illustré.
Un aperçu des datavisualisations
La datavisualisation est le meilleur moyen de rendre une donnée compréhensible par un public expert comme néophyte. Proposer dès la page d’accueil la datavisualisation d’une donnée utile donnera envie aux visiteurs d’explorer le reste du catalogue car ils comprendront que celui-ci aura été conçu pour inclure tous les usagers.
La donnée à la une
La mise en valeur d’une donnée importante permet d’attiser la curiosité du visiteur et de l’inciter à aller consulter le jeu de données associé, les datavisualisations et les réutilisations qui en ont été faites
L’actualité data de votre organisation
Ce bloc permet d’afficher les dernières mises à jour, actualités et événements et lien avec l’open data proposés par votre organisation.
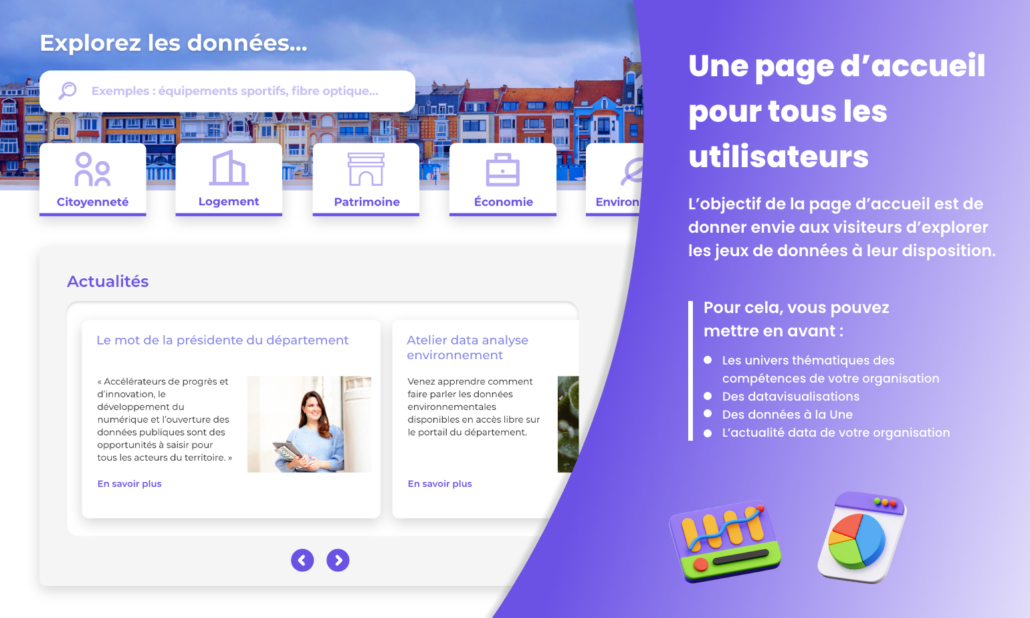
La page d’accueil donne le ton général de votre portail open data. Elle doit, en quelques secondes, présenter votre organisation, ses champs d’action et faire comprendre aux utilisateurs experts comme néophytes qu’ils y trouveront les informations et éléments qu’ils sont venus chercher.
Le catalogue de jeux de données, le cœur de votre portail open data
Le catalogue de jeux de données est le cœur du portail Open Data. Il doit permettre aux visiteurs de trouver rapidement les jeux de données qui leur seront utiles et de pourquoi pas en découvrir d’autres. Une de ses fonctions indispensables est l’exportation des données dans un fichier plat (CSV, Shapefile, GeoJSON…).
Système de filtres
Afin de faciliter au maximum la recherche de datasets, le catalogue doit comporter un système de filtres permettant de classer les jeux de données selon plusieurs caractéristiques : thème, format, date de mise à jour, métadonnées…
La carte d’identité
Les jeux de données doivent être présentés avec leurs métadonnées afin que les usagers aient toutes les cartes en main pour les utiliser au mieux. La carte d’identité du jeu de données peut-être plus ou moins fournie : certaines informations sont indispensables, comme le format, la date de publication ou encore l’entité ayant produit la donnée.
Certaines fonctionnalités ne sont pas indispensables mais permettent aux visiteurs non experts de se saisir des informations, comme une visualisation rapide du jeu de données (qui peut être cartographique si les données sont géolocalisées).
Afin d’inciter les visiteurs à utiliser la donnée dans leurs projets, on peut également proposer une galerie des réutilisations qui intègrent ce jeu de données.
Interactions avec le jeu de données
Vous pouvez proposer les interactions suivantes, qui rendront l’expérience online du jeu de données beaucoup plus intéressante :
- visualiser les données, avec une vue tableau et une vue carte si les données sont géographiques
- réutiliser facilement les données avec les outils ArcGIS : en accédant aux ressources de l’API, en créant une carte thématique (via ArcGIS Map Viewer), en créant une mise en récit (via ArcGIS StoryMaps)

Le catalogue de votre portail open data doit permettre à vos visiteurs :
– d’identifier rapidement les jeux de données qui les intéressent
– de pouvoir visualiser les données sous la forme de tableau et de carte interactive
– de pouvoir exporter et réutiliser les jeux de données
Le portrait de territoire pour illustrer les enjeux de votre organisation à l’échelle géographique
Si votre organisation a la charge de la gestion d’un territoire, pourquoi ne pas proposer une page « observatoire » permettant d’en réunir toutes des données clefs ?
Un observatoire permet de réunir sur la même interface les indicateurs clés des grands enjeux du territoire afin de les présenter aux visiteurs.
Ainsi, vous pouvez mettre en valeur ses spécificités et les actions menées par votre collectivité à travers des visualisations graphiques et géographiques multi-thématiques.

L’intégration d’une rubrique « Portrait de territoire » au portail open-data, permet aux visiteurs d’accéder aux indicateurs essentiels de son territoire. Elle offre ainsi un premier niveau de réutilisation / éditorialisation des données publiées sur le portail open-data et permet à tout un chacun de s’informer sur les chiffres clés reflétant les actions et politiques engagées sur le territoire.
Les pages thématiques pour donner des clefs de compréhension sur les sujets traités par votre organisation
Le classement en pages thématiques des jeux de données permet une centralisation des informations produites sur un sujet par votre organisation.
Ainsi, les visiteurs de votre portail peuvent en un clic avoir accès à une vue centrale sur le sujet qui les intéresse. Les pages thématiques permettent une éditorialisation importante de la donnée : les jeux de données sont présentés avec des clefs de lecture qui permettent à tous d’en saisir tous les enjeux, comme des datavisualisations, des FAQ ou encore des représentations cartographiques. Il est également intéressant de publier régulièrement des actualités sur le thème.
Les pages thématiques sont un moyen intéressant de mettre en avant les actions menées par votre organisation sur le sujet évoqué et d’orienter le visiteur en quête de réponses vers des solutions concrètes, comme des liens vers les services en charge de gérer la thématiques (logement, patrimoine, emploi, santé…).

Les pages thématiques permettent aux visiteurs de votre portail open data de se plonger dans les sujets traités par votre organisation et d’en tirer les informations les plus importantes. La part belle faite aux datavisualisations permet à tout un chacun de comprendre les informations essentielles et de vivre une expérience de la donnée à la hauteur des enjeux que celle-ci implique.
Une galerie de réutilisations pour inspirer et encourager les projets open data
La galerie de réutilisation permet de mettre en valeur les utilisations diverses et variées des sets de données proposés par votre organisation.
Cette galerie de réutilisation permet d’inspirer les visiteurs à prendre part au mouvement Open Data, à se former à l’usage de la donnée et à trouver des applications utiles de celle-ci. Il est intéressant de proposer des réutilisations réalisées à la fois par des professionnels de la donnée mais également par des amateurs, afin de montrer que tout le monde peut et doit s’en saisir.

L’open data doit devenir un cercle vertueux ! Plus la donnée est utilisée, plus on a envie d’utiliser la donnée. C’est pourquoi il est important d’avoir une galerie des réutilisations sur votre portail open data pour encourager les citoyens à prendre part au mouvement.
En conclusion…
Vous l’aurez compris, pour être accessible à tous les usagers, le portail open data de votre organisation doit être équilibré entre éléments répondants aux besoins des néophytes et des experts de la donnée.
Pour les experts, le catalogue est l’élément le plus important. Il doit permettre de rechercher et surtout de trouver des jeux de données pertinents avec facilité.
Pour les néophytes, le portrait de territoires, les pages thématiques et les autres réutilisations sont les éléments les plus importants. Ils permettent à tout à chacun de s’informer sur les chiffres clés de votre organisation, de mieux appréhender les données ouvertes sur le portail et d’encourager leurs réutilisations.
Alors, prêt à mettre en place un portail open data qui répond aux usages de tous ses visiteurs ?
À l’occasion de notre participation au concours Data City Paris, organisé par Numa, nous avons pu réfléchir aux problématiques associées au challenge : « dynamiser les commerces locaux». Ou comme nous l’avions compris, comment fournir à partir de données, une assistance aux choix de lieu d’implantation. C’est là tout l’intérêt du géodécisionnel : croiser des données géographiques pour visualiser un résultat, une véritable aide à la décision pour dynamiser ces implantations. N’ayant pas de données « à nous », nous avons cherché à rassembler celles disponibles qui nous semblaient pertinentes. Une des premières problématiques identifiée est la disparité des formats de jeux de données que nous souhaitions prendre en compte.
Pour illustrer notre réflexion, plaçons-nous dans le cas particulier où l’on cherche à trouver un lieu d’implantation dans le 19ème arrondissement pour un commerce, et faisons trois hypothèses (un peu simplistes mais ce n’est pas l’objet ici 🙂 ):
- il est préférable de ne pas trop avoir de concurrence à proximité,
- être proche des transports en commun est un avantage,
- plus la densité de population est forte, mieux c’est.
Dans ce cas relativement simple, prenons pour exemple trois jeux de données facilement récupérables en lien avec nos hypothèses:
- les commerces parisiens classés par type (opendata.Paris.fr),
- les données socio-démographiques : population et superficie par IRIS,
- les données de transport : ligne de transport en commun (données OSM)
Il est assez facile de visualiser ces trois jeux de données séparément, comme on peut le voir sur les images ci dessous :
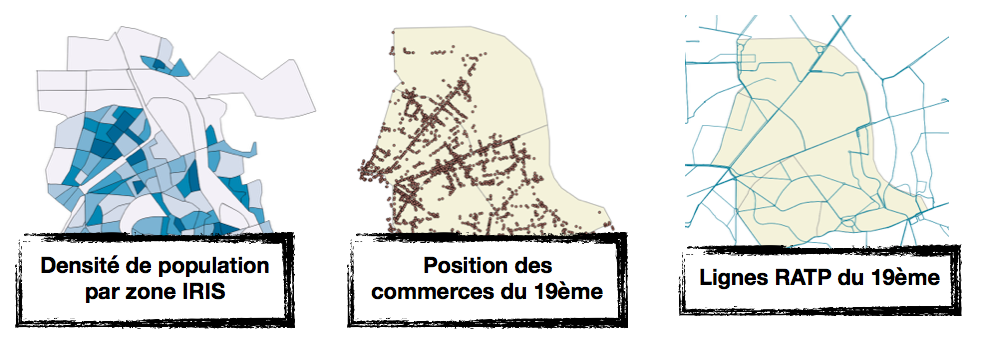
Cependant, avec les trois sources de données séparées, il est difficile de percevoir une information qui pourrait être utile. On pourrait penser les superposer, mais sous ces formats disparates cela ne permettrait pas forcément d’améliorer la lisibilité. L’idée qui nous est venue à l’esprit était de choisir un format géographique intermédiaire. Pour ce cas nous avons choisi de découper le territoire en hexagones. Ensuite, pour chacune des trois sources de données d’intérêts, nous l’avons transposée au sein de ce format intermédiaire, ainsi, chaque hexagone possède trois indicateurs :
- un score de densité, représenté ci-dessous de blanc (faible densité) à bleu foncé (forte densité),
- un nombre de commerces, représenté de beige (très faible) à marron (nombre élevé),
- un indicateur de présence de transports en commun, représenté en vert si positif.

Il est ensuite plus aisé d’avoir une représentation visuelle cohérente de ces ensembles de données.
Il suffit de « superposer » les trois sources de données transformées, c’est a dire de calculer un score d’attractivité à partir des trois indicateurs.
Ensuite, on peut rapidement percevoir une indication sur les zones pertinentes pour l’installation d’un nouveau commerce (relativement à nos hypothèses) : plus une zone tend vers le vert, plus elle est attractive.

Cette méthode, en plus de permettre une visualisation uniforme des différents jeux de données, facilite aussi par la suite l’application d’outils de data science avancés, qui permettent une assistance à la prise de décisions… mais ça, ce sera le sujet d’un prochain article !
Article rédigé par Gautier Daras.
Aujourd’hui on aborde un sujet souvent inconnu où mal compris par de nombreux gestionnaires : la contextualisation des données par rapport à leur environnement spatial. Cette contextualisation peut servir à mieux comprendre les performances et ainsi à permettre l’élaboration de stratégies adaptées : par exemple, savoir quels emplacements sont les plus propices à l’installation d’un magasin peut être utile pour développer une chaînes de franchises.
La localisation des infrastructures peut avoir une grande influence sur leurs performances. Ainsi, une connaissance des facteurs environnementaux qui peuvent avoir un impact sur ces performances peut être un atout majeur pour mieux gérer ces infrastructures. Dans notre exemple de chaine de magasins on peut imaginer que les performances soit influencées par des critères d’accessibilité, où de proximité de la concurrence.
Une manière d’acquérir cette connaissance est de se servir de l’aspect spatial inhérent à de nombreuses données : adresse, code postal, coordonnées GPS, etc… De nombreuses sources de données relatives à l’environnement d’une activité peuvent être utilisées : bases de données publiques, privées, fichiers, où même directement depuis des sites web. Tout élément qui dispose d’une information sur sa position peut être pris en compte et la donnée correspondante peut être mise en relation avec les données relatives aux infrastructures étudiées.
Ainsi, dans notre contexte d’illustration, les réseaux de transport en commun et les adresses des parkings d’une part, et les coordonnées des enseignes concurrentes d’autre part, pourraient être récupérées et mises en relation avec les performances des magasins existants.

Des outils d’extraction de connaissances à partir des données permettront ensuite de fournir des indicateurs pertinents pour les prises de décisions futures. Par exemple, dans le cas des magasins, quels critères d’accessibilité ont le plus d’influence : les parkings, les arrêts de bus ? Quelles sont les enseignes concurrentes les plus influentes ? Mieux vaut t’il s’en approcher pour profiter de leur clientèle, où s’en éloigner ? Les outils d’analyses de données peuvent apporter des éléments de réponses à ces questions.
Les différentes phases pour arriver à une solution adaptée au besoin réel sont complexes, et pour vous accompagner dans ce processus, Smart/Origin propose des solutions pour permettre la contextualisation des données, tant au niveau de la récupération des données externes, que dans leur analyse, jusqu’à leurs mises à disposition au travers d’outils de visualisation et d’exploration comme Dashboard et Cities.
Article rédigé par Gautier
« Les données sont une matière première vitale de l’économie de l’information, comme le charbon ou le minerai de fer l’étaient pendant la révolution industrielle. »
Steve Lohr, journaliste au New York Times
Oui l’OpenData est devenu incontournable, on en parle beaucoup et souvent, à se demander comment nous faisions pour vivre sans avant, n’est-ce pas. Pourtant, alors même que son nom sous-entend une parfaite libre utilisation, le plus souvent ces données dépendent de conditions d’utilisations et licences contraignantes pour les réutilisations. Tout n’est donc pas si rose dans le monde de l’OpenData.
Néanmoins, il faut bien lui accorder certains atouts, comme celui de créer de l’information, notamment en croisant ses données avec des données métiers. C’est là que prend tout son sens l’utilisation d’un outil de visualisation de données (dataviz) comme Dashboard : ajouter de la valeur aux données, c’est bien, les visualiser sur une carte interagissant avec des graphiques, c’est optimal pour en saisir la valeur.
Aujourd’hui, nous allons vous révéler toute la valeur ajoutée qu’il est possible de tirer du croisement de données avec de l’OpenData via trois cas d’usages : la prévision de fréquentation d’un musée, l’estimation du risque de catastrophes portant sur des structures touristiques et pour finir la détermination de cibles de prospect.
Commençons par un type de jeu de données assez courant sur les plateformes OpenData : les séries temporelles. Pour les non-statisticiens il s’agit tout simplement de fichiers dont l’information est rattaché à une notion de temps, comme des historiques de ventes ou de fréquentation. Ainsi à partir de données comme celles-ci, nous sommes en mesure de mettre en place un modèle de prédiction.
Cette information peut ensuite servir dans l’établissement d’un planning d’actions commerciales ou marketing par exemple.
À partir d’un jeu de données de la plateforme OpenData de la communauté d’agglomération du Grand Poitiers, portant sur la fréquentation des musées, nous avons mis en place un modèle de Holt-Winters de façon à obtenir des prévisions par triple lissage exponentiel.
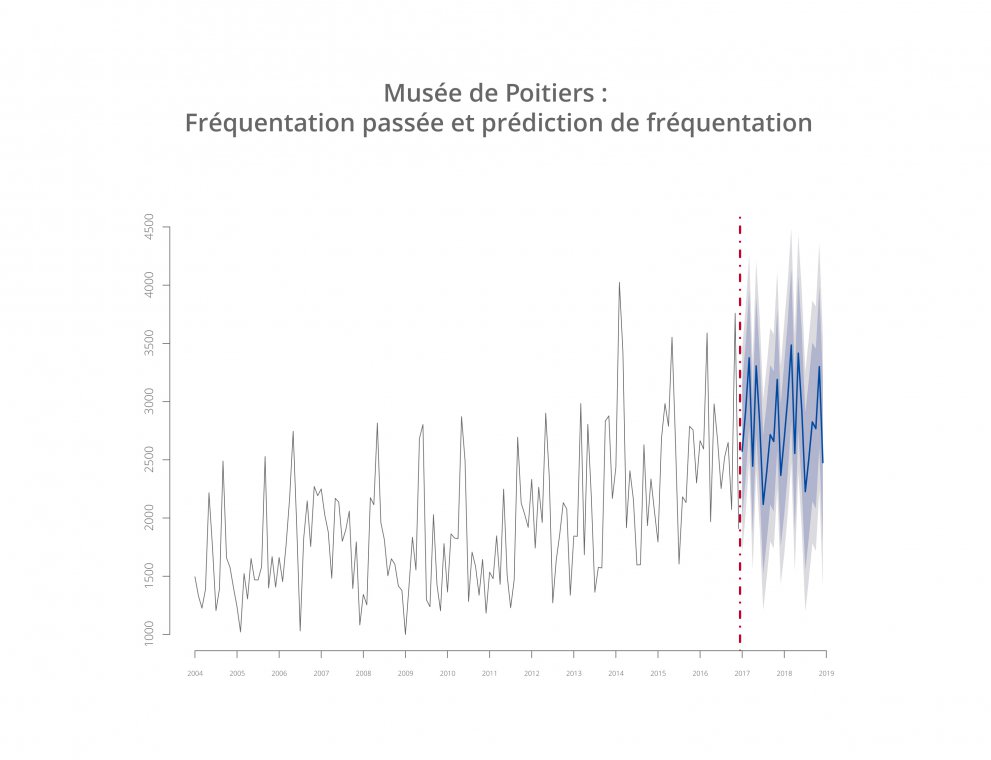
Grâce à ces prédictions directement exploitables dans Dashboard, la municipalité va pouvoir mettre en place des actions de promotions de ses musées lors des périodes creuses et ainsi dynamiser la fréquentation.
Le type de fichiers probablement le plus fréquent dans l’OpenData est celui de localisation. A partir de ce type de jeu de données, on peut calculer un tas d’indicateurs dépendants entre autres de la distance entre plusieurs éléments.
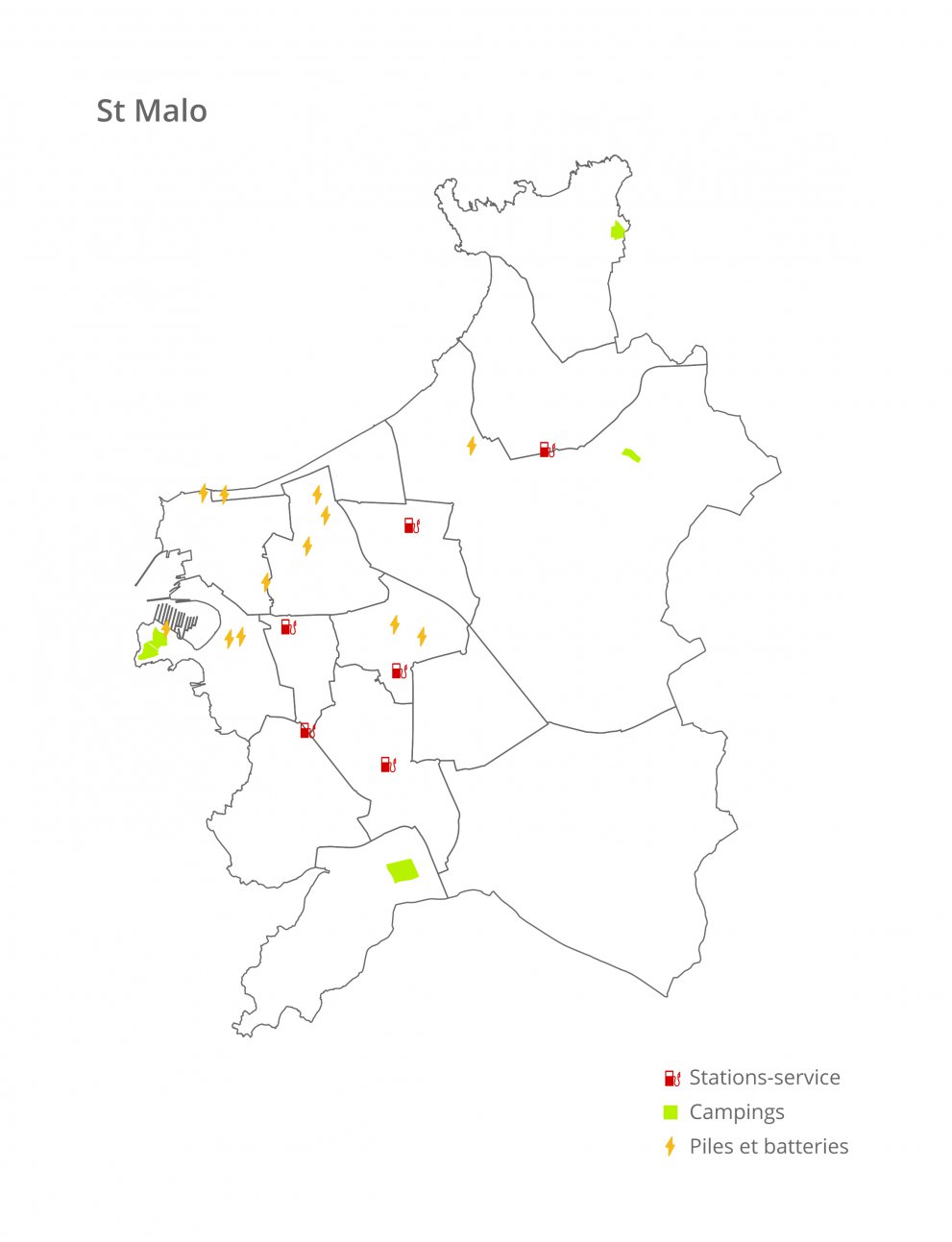
Ici, nous prenons l’exemple de la ville de St-Malo qui souhaite évaluer le niveau de risque qui porte sur chacun des campings de la ville.
Pour ce faire nous utilisons plusieurs fichiers du site OpenData de l’agglomération de St-Malo, pour récupérer la localisation de deux types de structures dangereuses identifiées par la ville : les stations-services et les conteneurs de piles et batteries usagées.
Ensuite il reste à calculer la distance euclidienne, c’est-à-dire la distance « à vol d’oiseau », entre un camping et chaque structure à risque, puis d’affecter une valeur proportionnelle à la distance. Le nombre de places du camping a également été pris en compte, puisque plus il y a de monde à évacuer et protéger, plus le danger augmente.
La municipalité va pouvoir adapter les mesures de sécurité et de protection, ainsi que les moyens de secours à l’aide de cette information. Elle pourra également autoriser ou interdire la construction de nouvelles structures dangereuses si le niveau de risque d’un camping dépasse alors un certain seuil. Dashboard devient alors un véritable outil de gestion opérationnelle pour aider à la prise de décision grâce à une visualisation géocentrique des données calculées.
La dernière possibilité de création d’information à partir de l’OpenData que nous vous proposons aujourd’hui est celle du calcul de densité proportionnelle d’un équipement par rapport à la population, en se servant d’un jeu de données de recensement de population et un autre de dénombrement d’équipements.
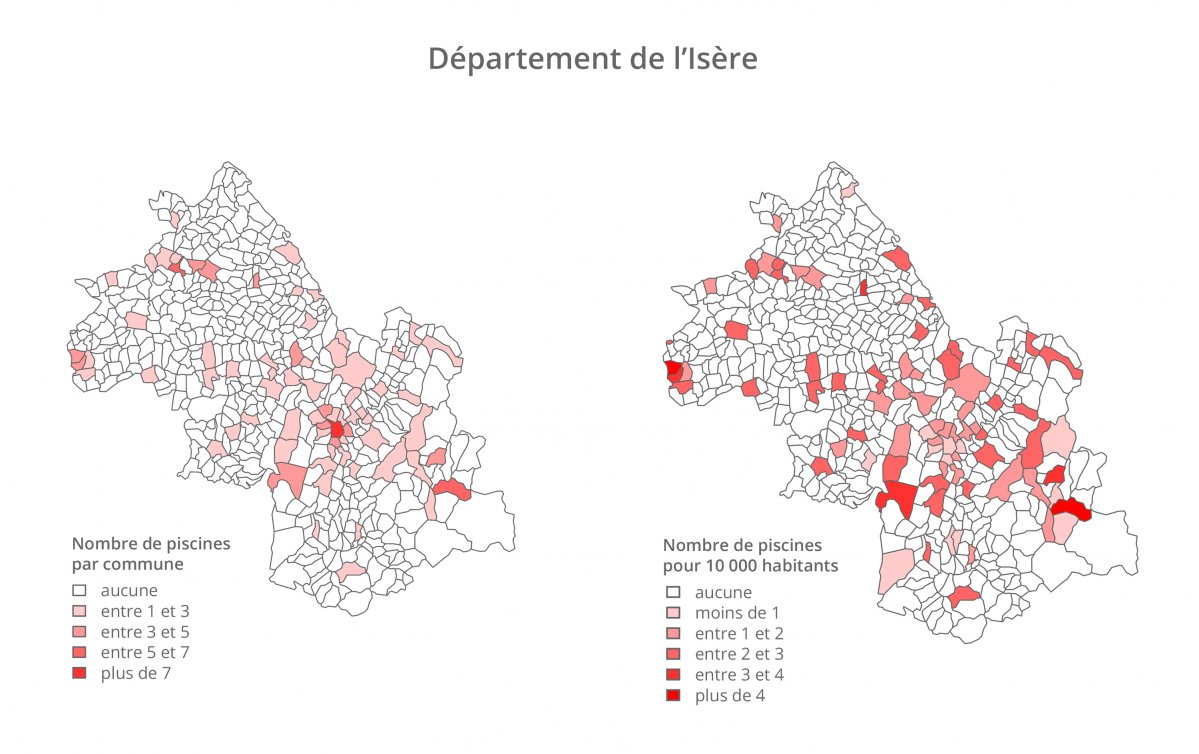
Prenons l’exemple d’une entreprise de BTP basée en Isère qui souhaite augmenter ses chantiers de piscines publiques. Avec les fichiers de l’INSEE, un de recensement de la population et un de dénombrement de structures sportives, nous pouvons lui fournir pour chaque commune de son département, le nombre de piscines pour 10 000 habitants.
Ici l’intérêt de Dashboard est de pouvoir comparer rapidement et visuellement des villes de tailles différentes. En effet comparer des effectifs bruts est trompeur. On le voit très bien dans le premier cas, Grenoble ressort très nettement sur la carte, alors que dans le second elle est très pale.
Avec cette information placée sur une carte (comme la seconde ici), la société va pouvoir cibler les communes à démarcher pour les pousser à faire des appels d’offres.
Brutes, les données « OpenData » sont quasi inutilisables, car bien souvent trop déconnectées d’un contexte d’utilisation. Tout l’intérêt de traiter celles-ci et de les croiser avec d’autres est justement d’obtenir de l’information, qui plus est, une information qui n’existe nulle part ailleurs.
Pour pouvoir visualiser vos données enrichies grâce à l’OpenData de manière géolocalisée, les consulter de façon dynamique et interactive avec un outil carto-centré, notre outil Dashboard se présente comme une solution incontournable. Vous pourrez choisir vos analyses, vos modules et obtenir un tableau de bord de suivi de vos données personnalisé, unique et surtout adapté à vos besoins.

![]()